
{kind=link}
In the world of mobile application development, dynamic and visually appealing content is paramount. While static assets bundled with an app have their place, the ability to fetch fresh content from the web opens up a universe of possibilities. This could range from creating a wallpaper application that pulls in daily images, a news aggregator that displays article thumbnails, or a prototyping tool that requires placeholder visuals. The core challenge, however, often lies in extracting this visual data from websites that don't offer a convenient public API. This is where the art of web scraping comes into play.
This article provides a comprehensive exploration of building an Android application designed to parse a website, extract image information, and display it in a clean, efficient user interface. We will delve into the architectural decisions, the core technologies used for parsing and display, and the practical challenges encountered in a real-world scenario, such as handling the Android activity lifecycle and dealing with modern web performance optimizations like lazy loading. Our primary tool for HTML parsing will be the powerful Jsoup library, complemented by Glide for seamless image loading and RecyclerView for building a scalable, performant list.
Crucially, we will also address the ethical and legal dimensions of web scraping. Extracting content from a website is a task that carries responsibility. To navigate these considerations, our project will specifically target Pixabay, a platform renowned for its library of high-quality, royalty-free images. This choice allows us to focus on the technical implementation without infringing on copyright, a principle that should be at the forefront of any scraping project.
Architectural Blueprint for a Scraping Application
Before writing a single line of code, it's essential to lay out a clear architectural plan. A well-designed structure separates concerns, making the code easier to understand, test, and maintain. For our image scraper, we can adopt a simple yet effective architecture that isolates network operations from the user interface.
The flow of data and control in our application can be broken down into three primary components:
- The User Interface (MainActivity): This is the user-facing component, responsible for displaying the list of images. It initiates the data request and, once the data is received, updates the UI to show the images. It should not contain any logic for fetching or parsing data directly. Its main job is to observe data changes and reflect them on the screen.
- The Data Layer (Networker/Repository): This component is the engine of our application. It handles all the heavy lifting: making network requests to the target website, receiving the raw HTML, and using Jsoup to parse that HTML to extract the relevant image URLs and metadata. It operates entirely on background threads to avoid blocking the UI.
- The Communication Bridge (Callback/ViewModel): A mechanism is needed for the Data Layer, after it has finished its background work, to pass the results back to the UI Layer. A simple callback interface is a direct way to achieve this. The MainActivity implements the interface, and the Networker calls its methods upon success or failure. In a more modern setup, we would use Android's ViewModel and LiveData to create a more robust, lifecycle-aware communication channel.
Our data model, let's call it ImageModel, will be a simple data class (or POJO in Java) that encapsulates the information for a single image, such as its source URL and potentially an alternative text description.
data class ImageModel(
val imageUrl: String,
val altText: String? = null
)
This separation ensures that if the website's HTML structure changes, we only need to update the logic within our Networker, leaving the MainActivity untouched. Similarly, if we decide to change our UI from a list to a grid, the Networker remains unaffected.
The Scraping Engine: Harnessing Jsoup for HTML Parsing
At the heart of our project is the task of converting a raw, unstructured HTML document into a structured list of image data. While one could technically use regular expressions for this, it's a notoriously brittle and error-prone approach. A far superior solution is to use a dedicated HTML parsing library like Jsoup.
Jsoup is a Java library (fully compatible with Kotlin) that provides a very convenient API for fetching URLs and extracting and manipulating data, using the best of DOM, CSS, and jquery-like methods.
Step 1: Inspecting the Target HTML
Before we can write our parsing code, we must understand the structure of the website we're targeting. This is an investigative step performed using the developer tools available in any modern web browser like Google Chrome or Firefox.
- Navigate to the Pixabay website.
- Right-click on one of the images you want to extract and select "Inspect". This will open the developer tools panel, highlighting the HTML element corresponding to that image.
- Carefully examine the HTML. Look for patterns. Are all images wrapped in a common container element (e.g., a
<div>with a specific class)? Does the<img>tag itself have a unique class or attribute that we can target?
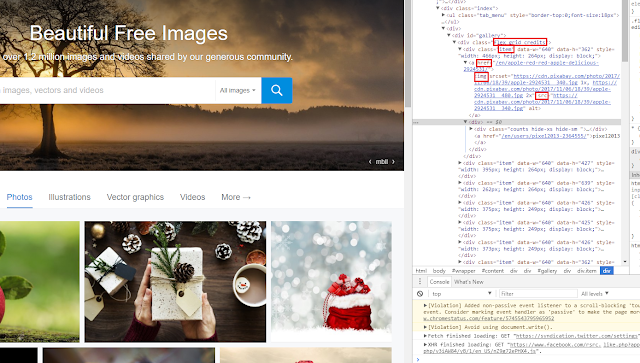
Through this inspection, we might find that each image is inside a <div> with the class "item", and the image itself is in an <img> tag with an attribute like src or data-src. This information is the key to our Jsoup implementation.
Step 2: Implementing the Jsoup Parser
With our target selectors identified, we can now build our Networker class. The core logic involves connecting to the URL, getting the HTML document, selecting the relevant elements, and iterating through them to build our list of ImageModel objects.
A crucial point to remember is that network operations are long-running and must not be performed on the Android main thread. Doing so would freeze the UI and eventually lead to an Application Not Responding (ANR) error. We must execute our Jsoup code on a background thread. A modern approach in Kotlin is to use coroutines, which simplify asynchronous code significantly.
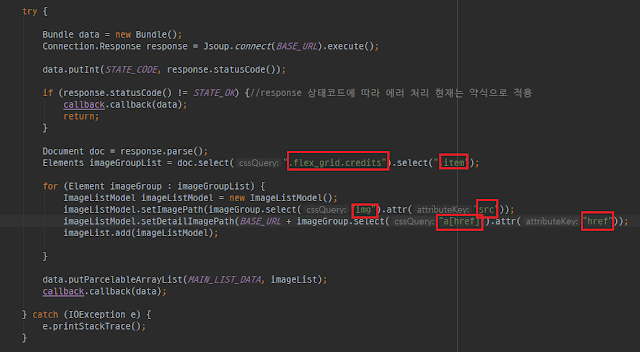
Here is a more complete conceptual example of what the parsing logic within our Networker might look like, using Kotlin Coroutines for background execution:
import kotlinx.coroutines.Dispatchers
import kotlinx.coroutines.withContext
import org.jsoup.Jsoup
class ImageScraper {
// Define a callback interface for returning results to the UI thread
interface ScrapeCallback {
fun onCompleted(images: List<ImageModel>)
fun onError(e: Exception)
}
suspend fun fetchImages(url: String): Result<List<ImageModel>> {
// Switch to the IO dispatcher for network operations
return withContext(Dispatchers.IO) {
try {
val imageList = mutableListOf<ImageModel>()
val document = Jsoup.connect(url).get()
// This selector is hypothetical and must be determined by inspecting the site.
// For example, find all divs with class 'image-container'
val elements = document.select("div.item a img")
for (element in elements) {
// Extract the image URL. Sometimes it's in 'src', sometimes 'data-src' for lazy loading.
val imageUrl = element.attr("src")
if (imageUrl.startsWith("http")) { // Basic validation
val altText = element.attr("alt")
imageList.add(ImageModel(imageUrl, altText))
}
}
Result.success(imageList)
} catch (e: Exception) {
// Catch any exceptions during network call or parsing
Result.failure(e)
}
}
}
}
Crafting an Efficient and Responsive User Interface
Once we have the data, the next challenge is to display it effectively. For a potentially long list of images, the most performant and standard component in Android is the RecyclerView.
Using RecyclerView for Scalable Lists
RecyclerView is designed for efficiency. It recycles views that scroll off-screen to display new items scrolling on-screen, avoiding the expensive process of creating new view objects for every single item in the list. This requires an Adapter to bridge our data (the list of ImageModel objects) and the UI, and a ViewHolder to hold references to the individual views within each list item (like the ImageView).
Performance Tip: Setting Click Listeners
A common performance pitfall is setting click listeners inside the onBindViewHolder method of the adapter. This method is called every time a view is about to be displayed, which happens frequently during scrolling. Creating a new listener object each time is wasteful and can contribute to stuttering or "jank" in the scroll performance.
A more efficient approach is to set the listener once, within the onCreateViewHolder method. This method is only called when a new ViewHolder instance needs to be created, which is a much less frequent event.
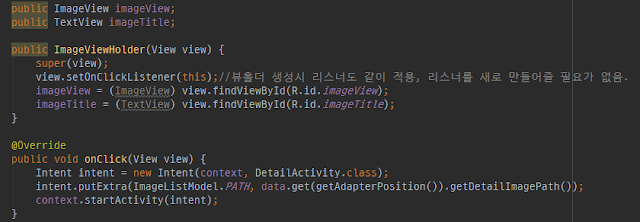
class ImageViewHolder(
itemView: View,
private val onItemClicked: (position: Int) -> Unit
) : RecyclerView.ViewHolder(itemView) {
private val imageView: ImageView = itemView.findViewById(R.id.item_image)
init {
itemView.setOnClickListener {
// Use adapterPosition to get the correct item index
onItemClicked(adapterPosition)
}
}
fun bind(imageModel: ImageModel) {
// Image loading logic goes here
}
}
Seamless Image Loading with Glide
Loading images from the network directly into an ImageView is a complex task. You need to handle background threading, caching (both in memory and on disk), bitmap decoding, and error states. Fortunately, powerful libraries like Glide handle all this complexity for us with a simple, fluent API.
Using Glide, we can load an image from a URL into an ImageView with a single line of code. Furthermore, it provides essential features for a professional user experience, such as placeholders and error images.
- Placeholder: An image that is shown while the actual image is being downloaded and decoded. This prevents empty spaces in the UI and signals to the user that content is loading.
- Error: An image that is shown if the image fails to load for any reason (e.g., network error, invalid URL). This is much better than showing a broken image icon or an empty space.

The implementation within the ViewHolder's bind method would look like this:
fun bind(imageModel: ImageModel) {
Glide.with(itemView.context)
.load(imageModel.imageUrl)
.placeholder(R.drawable.ic_placeholder) // Your placeholder drawable
.error(R.drawable.ic_error) // Your error drawable
.centerCrop()
.into(imageView)
}
Handling Configuration Changes Gracefully
A fundamental aspect of Android development is handling configuration changes, with screen rotation being the most common example. By default, when a user rotates their device, Android destroys and recreates the current `Activity`. This can be problematic for our app, as it would lose the entire list of scraped images and trigger a new network request, which is inefficient and provides a poor user experience.
The "Easy" but Limited Fix: `android:configChanges`
A quick way to prevent the Activity from being recreated is to declare that you will handle the configuration change yourself. This is done by adding the `android:configChanges` attribute to your activity's declaration in the `AndroidManifest.xml` file.
<activity
android:name=".MainActivity"
android:configChanges="orientation|screenSize|keyboardHidden">
...
</activity>
While this works, it is often considered a shortcut and not a best practice for complex applications. It makes you responsible for manually adjusting layouts and resources, and it sidesteps the standard Android lifecycle, which can lead to other issues. It's a viable option for simple cases but is not a scalable solution.
The Modern Solution: ViewModel and LiveData
The recommended, modern approach is to use the Android Architecture Components, specifically `ViewModel`. A `ViewModel` is a lifecycle-aware component designed to store and manage UI-related data. Crucially, a `ViewModel` survives configuration changes. When the `Activity` is recreated after rotation, the new `Activity` instance connects to the *same* existing `ViewModel` instance, which still holds the list of images.
The flow would be:
- The `MainActivity` requests the `ViewModel` to fetch the data.
- The `ViewModel` calls our `ImageScraper` (on a coroutine scope tied to the ViewModel).
- The scraper returns the data, which the `ViewModel` places into a `LiveData` object.
- The `MainActivity` observes this `LiveData`. When the data changes, the observer's callback is triggered, and the UI is updated.
This architecture cleanly separates data from the UI and gracefully handles configuration changes without needing to re-fetch data, resulting in a much more robust and efficient application.
Advanced Scraping Challenge: Lazy Loading
Modern websites heavily optimize for performance, and a common technique is "lazy loading" of images. This means that images that are not yet visible on the screen (i.e., "below the fold") are not loaded initially. Their `src` attribute might be empty or point to a low-quality placeholder. The actual image URL is often stored in a different attribute, like `data-src` or `data-url`. Only when the user scrolls down and the image enters the viewport does JavaScript kick in to move the URL from the data attribute to the `src` attribute, triggering the load.
This poses a significant problem for a simple scraper like ours. Jsoup fetches the initial HTML document *before* any JavaScript has executed. Consequently, it will only see the empty or placeholder `src` attributes, and our scraper will fail to extract the correct image URLs.
Strategies to Overcome Lazy Loading
While the original project left this issue unhandled, several strategies can be employed to combat it:
- Inspect Data Attributes: The simplest solution is to check if the real URL is present in a different attribute. Re-inspect the `
` tag in your browser's developer tools and look for attributes like `data-src`. If you find one, simply modify your Jsoup code to extract from that attribute instead of `src`.
- Find the Embedded Data Source: Often, the data for the entire page, including the real image URLs, is embedded within the initial HTML as a JSON object inside a `<script>` tag. You can use Jsoup to select the correct script tag, extract its text content, and then use a JSON parsing library (like Gson or Moshi) to parse this text into your data models. This is a very reliable method if available.
- Analyze Network Requests: A more advanced technique involves using the "Network" tab in your browser's developer tools. As you scroll down the page, you can monitor the XHR/Fetch requests that the page's JavaScript makes to the server to get the data for the next batch of images. These requests often go to a hidden API endpoint that returns clean, structured JSON data. If you can reverse-engineer this API call, you can have your app call it directly, bypassing HTML scraping entirely. This is the most robust and preferred method.
Conclusion and Project Source
Building a web scraper on Android is a fascinating project that combines network programming, data parsing, and UI design. Through this exploration, we've seen how to create a solid architecture, leverage powerful libraries like Jsoup and Glide, and build a performant UI with RecyclerView. We've also delved into crucial real-world considerations like handling the Android lifecycle and tackling advanced website features like lazy loading.
Remember that web scraping should always be done responsibly. Respect the website's terms of service, check for a `robots.txt` file, and always prefer a public API if one is available. The techniques discussed here provide a powerful toolset, and with great power comes great responsibility.
Download the Example Source Code
To further explore the concepts discussed and see a practical implementation, you can download the example project source code from the link below:
Download Example Source Code
Post a Comment